
티스토리 뷰
본 게시글은 NLP in Korean의 The Illustrated Transformer 게시글을 정리한 것입니다. Transformer를 공부하시는 분들은 시각적인 자료로 쉽게 설명되어 있으니 한번 보시는 것을 추천드립니다.
목차
- Introduction
- 개괄적인 수준의 설명
- 벡터들을 기준으로 그림 그려보기
- 이제 Encoding을 해봅시다!
- 크게 크게 살펴보는 Self-Attention
- Self-Attention 을 더 자세히 보겠습니다.
- Self-attention 의 행렬 계산
- The Beast With Many Heads
- Positional Encoding 을 이용해서 시퀀스의 순서 나타내기
- The Residuals
- The Decoder Side
- 마지막 Linear Layer과 Softmax Layer
- 학습 과정 다시 보기
- Loss Function
- 더 깊이 Transformer 알아보기
Introduction
2017 NIPS에서 Google이 소개했던 Transformer는 NLP 학계에서 정말 큰 주목을 끌었는데요, 어떻게 보면 기존의 CNN과 RNN 이 주를 이뤘던 기존의 연구들에서 벗어나 아예 새로운 모델을 제안했기 때문이지 않을까 싶습니다.
이 모델의 핵심을 정리해보자면, multi-head self-attention을 이용해 sequential computation을 줄여 더 많은 부분을 병렬 처리가 가능하게 만들면서 동시에 더 많은 단어들 간 dependency를 모델링한다는 것입니다.
Attention 은 신경망 기계 번역과 그 응용 분야들의 성능을 향상하는데 도움이 된 컨셉입니다. 이번 글에서는 우리는 이 attention을 활용한 모델인 Transformer에 대해 다룰 것입니다
Transformer 모델은 몇몇의 테스트에서 기존의 seq2seq를 활용한 구글 신경망 번역 시스템보다 좋은 성능을 보입니다. 하지만 이것의 가장 큰 장점은 병렬 처리에 관한 부분입니다.
개괄적인 설명
모델의 자세한 부분을 무시하고, 이를 하나의 black box라고 보겠습니다.
기계 번역의 경우를 생각해본다면, 모델은 어떤 한 언어로 된 하나의 문장을 입력으로 받아 다른 언어로 된 번역을 출력으로 내놓을 것입니다.

black box를 열어 보게 되면 우리는 encoding 부분, decoding 부분, 그리고 그 사이를 이어주는 connection들을 보게 됩니다.

encoding 부분은 여러 개의 encoder를 쌓아 올려 만든 것입니다 (각자의 세팅에 맞게 얼마든지 변경하여 실험할 수 있습니다)
decoding 부분은 encoding 부분과 동일한 개수만큼의 decoder를 쌓은 것을 말합니다.

encoder 들은 모두 정확히 똑같은 구조를 가지고 있습니다 (그러나 그들 간에 같은 weight을 공유하진 않습니다).
하나의 encoder를 나눠보면 아래와 같이 두 개의 sub-layer으로 구성되어 있습니다:
(Self Attention -> Feed Forward NN)

인코더에 들어온 입력은 일단 먼저 self-attention layer을 지나가게 됩니다
self-attention layer는 encoder가 하나의 특정한 단어를 encode 하기 위해서 입력 내의 모든 다른 단어들과의 관계를 살펴봅니다.
입력이 self-attention 층을 통과하여 나온 출력은 다시 feed-forward 신경망으로 들어가게 됩니다.
똑같은 feed-forward 신경망이 각 위치의 단어마다 독립적으로 적용돼 출력을 만듭니다.

decoder 또한 encoder에 있는 두 layer 모두를 가지고 있습니다.
그러나 그 두 층 사이에 seq2seq 모델의 attention과 비슷한 encoder-decoder attention 이 포함되어 있습니다.
이는 decoder가 입력 문장 중에서 각 타임 스텝에서 가장 관련 있는 부분에 집중할 수 있도록 해줍니다.
(Self Attention -> Endocer Decoder Attention -> FFNN)
벡터를 기준으로 그림 그려보기
Transformer 모델의 주요 부분들에 대해서 다 알아보았습니다.
이제 입력으로 들어와서 출력이 될 때까지 이 부분들 사이를 지나가며 변환될 벡터/텐서들을 기준으로 모델을 살펴보도록 하겠습니다
현대에 들어 대부분 NLP 관련 모델에서 그러듯, 먼저 입력 단어들을 embedding 알고리즘을 이용해 벡터로 바꾸는 것부터 해야 합니다.

각 단어들은 크기 512의 벡터 하나로 embed 됩니다. (변환된 벡터들을 위와 같은 간단한 박스로 나타내겠습니다)
embedding은 가장 밑단의 encoder에서만 일어납니다.
우리는 이렇게 뭉뚱그려 표현할 수 있게 됩니다
-
모든 encoder 들은 크기 512의 벡터의 리스트를 입력으로 받습니다
-
이 벡터는 가장 밑단의 encoder의 경우에는 word embedding이 될 것이고, 다른 encoder들에서는 바로 전의 encoder의 출력일 것입니다
-
이 벡터 리스트의 사이즈는 hyperparameter로 우리가 마음대로 정할 수 있습니다(가장 간단하게 생각한다면 학습 데이터 셋에서 가장 긴 문장의 길이로 둘 수 있습니다.)
입력 문장의 단어들을 embedding 후에, 각 단어에 해당하는 벡터들은 encoder 내의 두 개의 sub-layer으로 들어가게 됩니다.

여기서 각 위치에 있는 각 단어가 그만의 path를 통해 encoder에서 흘러간다는 Transformer 모델의 주요 성질을 볼 수 있습니다
Self-attention 층에서 이 위치에 따른 path들 사이에 다 dependency가 있습니다.
반면 feed-forward 층은 이런 dependency가 없기 때문에 feed-forward layer 내의 이 다양한 path 들은 병렬 처리될 수 있습니다.
이 예시를 조금 더 짧은 문장으로 바꾸어 encoder의 각 sub-layer에서 무슨 일이 일어나는지를 자세히 보도록 하겠습니다.
Encoding
encoder는 입력으로 벡터들의 리스트를 받습니다. 이 리스트를 먼저 self-attention layer에, 그다음으로 feed-forward 신경망에 통과시키고 그 결과물을 그다음 encoder에게 전달합니다.
Vector list -> Encoder1(Self Attention) -> Encoder1(Feed Forward) -> Encoder2(Self Attention) -> Encoder2(Feed Forward)
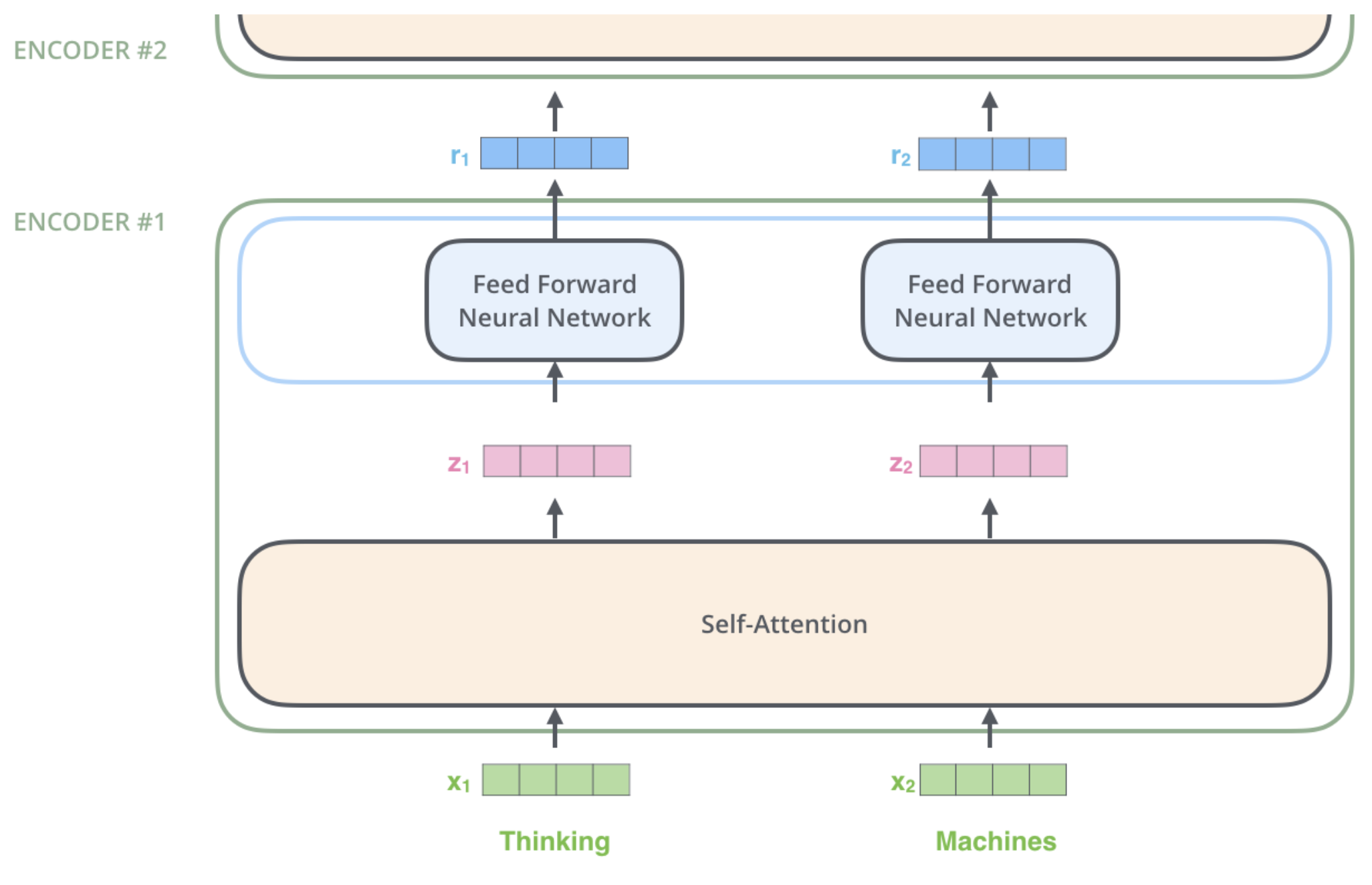
각 위치의 단어들은 각각 다른 self-encoding 과정을 거칩니다.
그다음으로는 모두에게 같은 과정인 feed-forward 신경망을 거칩니다.
Self-Attention 살펴보기
self-attention 개념이 어떻게 작동하는지 자세히 알아보도록 하겠습니다.
다음 문장을 우리가 번역하고 싶은 문장이라고 치겠습니다:
“그 동물은 길을 건너지 않았다 왜냐하면 그것은 너무 피곤했기 때문이다”
이 문장에서 “그것” 이 가리키는 것은 무엇일까요? “그것”은 길을 말하는 것일까요 아니면 동물을 말하는 것일까요?
사람에게는 간단한 질문이지만 신경망 모델에게는 그렇게 간단하지만은 않은 문제입니다.
모델이 “그것은”이라는 단어를 처리할 때, 모델은 self-attention을 이용하여 “그것”과 “동물”을 연결할 수 있습니다.
모델이 입력 문장 내의 각 단어를 처리해 나감에 따라, self-attention은 입력 문장 내의 다른 위치에 있는 단어들을 보고 거기서 힌트를 받아 현재 타겟 위치의 단어를 더 잘 encoding 할 수 있습니다.
RNN이 hidden state를 유지하고 업데이트함으로써 현재 처리 중인 단어에 어떻게 과거의 단어들에서 나온 맥락을 연관시키는지 생각해보세요. 그와 동일하게 Transformer에게는 이 self-attention이 현재 처리 중인 단어에 다른 연관 있는 단어들의 맥락을 불어넣어주는 method입니다.

“그것”이라는 단어를 encoding 할 때, attention 메커니즘은 입력의 여러 단어들 중에서 “그 동물”이라는 단어에 집중하고 이 단어의 의미 중 일부를 “그것”이라는 단어를 encoding 할 때 이용합니다.
Tensor2Tensor 노트북에서 Transformer 모델을 불러와서 인터랙티브 한 시각화를 통해 여러 가지 사항들을 직접 실험해보실 수 있으니 한 번 확인해보세요.
Self-Attention 자세히 알아보기
여러 가지 벡터들을 통해서 어떻게 self-attention을 계산할 수 있는지 보겠습니다.
그 후 행렬을 이용해서 이것이 실제로 어떻게 구현돼 있는지 확인하겠습니다.
self-attention 계산의 가장 첫 단계는 encoder에 입력된 벡터들 (이 경우에서는 각 단어의 embedding 벡터입니다)에게서 부터 각 3개의 벡터를 만들어내는 일입니다.
우리는 각 단어에 대해서 Query 벡터, Key 벡터, 그리고 Value 벡터를 생성합니다.
이 벡터들은 입력 벡터에 대해서 세 개의 학습 가능한 행렬들을 각각 곱함으로써 만들어집니다.
한 가지 짚고 넘어갈 것은 이 새로운 벡터들이 기존의 벡터들 보다 더 작은 사이즈를 가진다는 것입니다.
기존의 입력 벡터들은 크기가 512인 반면 이 새로운 벡터들은 크기가 64입니다.
그러나 그들이 꼭 이렇게 더 작아야만 하는 것은 아니며, 이것은 그저 multi-head attention의 계산 복잡도를 일정하게 만들고자 내린 구조적인 선택일 뿐입니다.

x1에 weight 행렬인 WQ를 곱하여 현재 단어와 연관된 query 벡터인 q1를 생성합니다.
같은 방법으로 입력 문장에 있는 각 단어에 대한 query, key, value 벡터를 만들 수 있습니다.
정확히 이 query, key, value 벡터란 무엇을 의미하는 것일까요?
attention에 대해서 생각하고 계산하려 할 때 도움이 되는 추상적인 개념입니다.
attention 이 어떻게 계산되는지를 알게 되면, 세 개의 벡터들이 어떤 역할을 하는지 알 수 있게 됩니다.
self-attention 계산의 두 번째 스텝은 점수를 계산하는 것입니다.
아래 이미지의 첫 번째 단어인 “Thinking”에 대해서 self-attention을 계산한다고 하겠습니다.
우리는 단어와 입력 문장 속의 다른 모든 단어들에 대해서 각각 점수를 계산하여야 합니다.
점수는 현재 위치의 이 단어를 encode 할 때 다른 단어들에 대해서 얼마나 집중을 해야 할지를 결정합니다.
점수는 현재 단어의 query vector와 점수를 매기려 하는 다른 위치에 있는 단어의 key vector의 내적으로 계산됩니다.
다시 말해, 우리가 위치 #1에 있는 단어에 대해서 self-attention을 계산한다 했을 때, 첫 번째 점수는 q1과 k1의 내적일 것입니다.
그리고 동일하게 두 번째 점수는 q1과 k2의 내적일 것입니다.

세 번째와 네 번째 단계는 이 점수들을 8로 나누는 것입니다.
8이란 숫자는 key 벡터의 사이즈인 64의 제곱 근이라는 식으로 계산이 된 것입니다.
나눗셈을 통해 우리는 더 안정적인 gradient를 가지게 됩니다.
이 값을 softmax 계산을 통과시켜 모든 점수들을 양수로 만들고 그 합을 1로 만들어 줍니다.

softmax 점수는 현재 위치의 단어의 encoding에 있어서 각 단어들의 표현이 얼마나 들어갈 것인지를 결정합니다.
당연하게 현재 위치의 단어가 가장 높은 점수를 가지며 가장 많은 부분을 차지하게 되겠지만, 가끔은 현재 단어에 관련이 있는 다른 단어에 대한 정보가 들어가는 것이 도움이 됩니다.
다섯 번째 단계는 이제 입력의 각 단어들의 value 벡터에 이 점수를 곱하는 것입니다.
이것을 하는 이유는 우리가 집중을 하고 싶은 관련이 있는 단어들은 그래도 남겨두고, 관련이 없는 단어들은 0.001과 같은 작은 숫자 (점수)를 곱해 없애버리기 위함입니다.
마지막 여섯 번째 단계는 이 점수로 곱해진 weighted value 벡터들을 다 합해 버리는 것입니다.
이 단계의 출력이 바로 현재 위치에 대한 self-attention layer의 출력이 됩니다.

여섯 가지 과정이 바로 self-attention의 계산 과정입니다. 우리는 이 결과로 나온 벡터를 feed-forward 신경망으로 보내게 됩니다.
그러나 실제 구현에서는 빠른 속도를 위해 이 모든 과정들이 벡터가 아닌 행렬의 형태로 진행됩니다.
이때까지 각 단어 레벨에서의 계산과 그 이유에 대해서 얘기해봤다면, 이제 이 행렬 레벨의 계산을 살펴보도록 하겠습니다.
Self-attention의 행렬 계산
가장 첫 스텝은 입력 문장에 대해서 Query, Key, Value 행렬들을 계산하는 것입니다. 우리의 입력 벡터들 (혹은 embedding 벡터들)을 하나의 행렬 X로 쌓아 올리고, 그것을 우리가 학습할 weight 행렬들인 WQ, WK, WV로 곱합니다.

행렬 X의 각 행은 입력 문장의 각 단어에 해당합니다. 우리는 여기서 다시 한번 embedding 벡터들 (크기 512, 그림에서는 4)과 query/key/value 벡터들 (크기 64, 그림에서는 3) 간의 크기 차이를 볼 수 있습니다.
마지막으로, 우리는 현재 행렬을 이용하고 있으므로 앞서 설명했던 self-attention 계산 단계 2부터 6까지를 하나의 식으로 압축할 수 있습니다.

The Beast With Many Heads
본 논문은 이 self-attention layer에다 “multi-headed” attention이라는 메커니즘을 더해 더욱더 이를 개선합니다.
이것은 두 가지 방법으로 attention layer의 성능을 향상시킵니다:
-
모델이 다른 위치에 집중하는 능력을 확장시킵니다. 위의 예시에서는 z1 이 모든 다른 단어들의 encoding을 조금씩 포함했지만, 사실 이것은 실제 자기 자신에게만 높은 점수를 줘 자신만을 포함해도 됐을 것입니다. 이것은 “그 동물은 길을 건너지 않았다 왜냐하면 그것은 너무 피곤했기 때문이다” 와 같은 문장을 번역할 때 “그것”이 무엇을 가리키는지에 대해 알아낼 때 유용합니다.
-
attention layer 가 여러 개의 “representation 공간”을 가지게 해 줍니다. 계속해서 보겠지만, multi-headed attention을 이용함으로써 우리는 여러 개의 query/key/value weight 행렬들을 가지게 됩니다 (논문에서 제안된 구조는 8개의 attention heads를 가지므로 우리는 각 encoder/decoder마다 이런 8개의 세트를 가지게 되는 것입니다). 이 각각의 query/key/value set는 랜덤으로 초기화되어 학습됩니다. 학습이 된 후 각각의 세트는 입력 벡터들에 곱해져 벡터들을 각 목적에 맞게 투영시키게 됩니다. 이러한 세트가 여러 개 있다는 것은 각 벡터들을 각각 다른 representation 공간으로 나타낸 다는 것을 의미합니다

multi-headed attention을 이용하기 위해서 우리는 각 head에 각각의 다른 query/key/value weight 행렬들을 모델에 가지게 됩니다.
이전에 설명한 것과 같이 입력 벡터들의 모음인 행렬 X를 WQ/WK/WV 행렬들로 곱해 각 head에 대한 Q/K/V 행렬들을 생성합니다.
위에 설명했던 대로 같은 self-attention 계산 과정을 8개의 다른 weight 행렬들에 대해 8번 거치게 되면, 우리는 8개의 서로 다른 Z 행렬을 가지게 됩니다.

그러나 문제는 이 8개의 행렬을 바로 feed-forward layer으로 보낼 수 없다는 것입니다. feed-forward layer 은 한 위치에 대해 오직 한 개의 행렬만을 input으로 받을 수 있습니다. 그러므로 우리는 이 8개의 행렬을 하나의 행렬로 합치는 방법을 고안해 내야 합니다.
어떻게 할 수 있을까요? 간단합니다. 일단 모두 이어 붙여서 하나의 행렬로 만들어버리고, 그다음 하나의 또 다른 weight 행렬인 W0을 곱해버립니다. 그 결과는 Z 행렬이 되고 FFNN으로 보낼 수 있게 됩니다.

사실상 multi-headed self-attention 은 이게 다입니다. 비록 여러 개의 행렬들이 등장하긴 했지만요. 이제 이 모든 것을 하나의 그림으로 표현해서 모든 과정을 한눈에 정리해보도록 하겠습니다.

여기까지 attention heads에 대해서 설명해 보았는데요, 이제 다시 우리의 예제 문장을 multi-head attention과 함께 보도록 하겠습니다. 그중에서도 특히 “그것” 이란 단어를 encode 할 때 여러 개의 attention 이 각각 어디에 집중하는지를 보도록 하겠습니다

우리가 “그것” 이란 단어를 encode 할 때, 주황색의 attention head는 “그 동물”에 가장 집중하고 있는 반면 초록색의 head는 “피곤”이라는 단어에 집중을 하고 있습니다. 모델은 이 두 개의 attention head를 이용하여 “동물”과 “피곤” 두 단어 모두에 대한 representation을 “그것”의 representation에 포함시킬 수 있습니다.
그러나 이 모든 attention head들을 하나의 그림으로 표현하면, 이제 attention의 의미는 해석하기가 어려워집니다

Positional Encoding을 이용해서 시퀀스의 순서 나타내기
우리가 이때까지 설명해온 Transformer 모델에서 한 가지 부족한 부분은 이 모델이 입력 문장에서 단어들의 순서에 대해서 고려하고 있지 않다는 점입니다.
이것을 추가하기 위해서, Transformer 모델은 각각의 입력 embedding에 “positional encoding”이라고 불리는 하나의 벡터를 추가합니다. 이 벡터들은 모델이 학습하는 특정한 패턴을 따르는데, 이러한 패턴은 모델이 각 단어의 위치와 시퀀스 내의 다른 단어 간의 위치 차이에 대한 정보를 알 수 있게 해 줍니다. 이 벡터들을 추가하기로 한 배경에는 이 값들을 단어들의 embedding에 추가하는 것이 query/key/value 벡터들로 나중에 투영되었을 때 단어들 간의 거리를 늘릴 수 있다는 점이 있습니다.

모델에게 단어의 순서에 대한 정보를 주기 위하여, 위치 별로 특정한 패턴을 따르는 positional encoding 벡터들을 추가합니다.
만약 embedding의 사이즈가 4라고 가정한다면, 실제로 각 위치에 따른 positional encoding 은 아래와 같은 것입니다
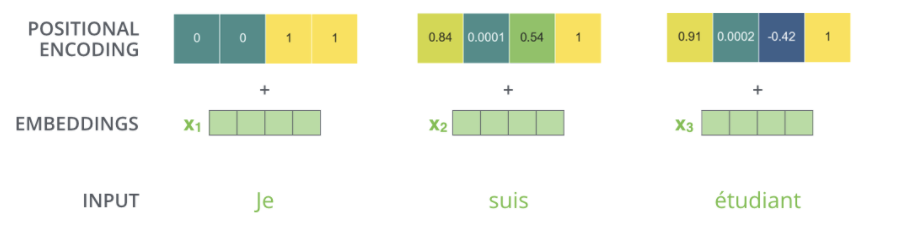
실제로는 이 패턴이 어떻게 될까요?
다음 그림을 보겠습니다. 그림에서 각 행은 하나의 벡터에 대한 positional encoding에 해당합니다. 그러므로 첫 번째 행은 우리가 입력 문장의 첫 번째 단어의 embedding 벡터에 더할 positional encoding 벡터입니다. 각 행은 사이즈 512인 즉 512개의 셀을 가진 벡터이며 각 셀의 값은 1과 -1 사이를 가집니다. 다음 그림에서는 이 셀들의 값들에 대해 색깔을 다르게 나타내어 positional encoding 벡터들이 가지는 패턴을 볼 수 있도록 시각화하였습니다.

20개의 단어와 크기 512인 embedding에 대한 positional encoding의 실제 예시입니다. 그림에서 볼 수 있듯이 이 벡터들은 중간 부분이 반으로 나눠져 있습니다. 그 이유는 바로 왼쪽 반은 (크기 256) sine 함수에 의해서 생성되었고, 나머지 오른쪽 반은 또 다른 함수인 cosine 함수에 의해 생성되었기 때문입니다. 그 후 이 두 값들은 연결되어 하나의 positional encoding 벡터를 이루고 있습니다.
이 positional encoding에 대한 식은 논문의 section 3.5에 설명되어 있습니다. 실제로 이 벡터들을 생성하는 부분의 코드인 get_timing_signal_1d()를 참고하셔도 좋습니다. 이것은 사실 positional encoding에 대해서만 가능한 방법은 아닙니다. 하지만 이것은 본 적이 없는 길이의 시퀀스에 대해서도 positional encoding을 생성할 수 있기 때문에 scalability에서 큰 이점을 가집니다 (예를 들어, 이미 학습된 모델이 자신의 학습 데이터보다도 더 긴 문장에 대해서 번역을 해야 할 때에도 현재의 sine과 cosine으로 이루어진 식은 positional encoding을 생성해낼 수 있습니다).
The Residuals
encoder를 넘어가기 전에 그의 구조에서 한 가지 더 언급하고 넘어가야 하는 사항은, 각 encoder 내의 sub-layer 가 residual connection으로 연결되어 있으며, 그 후에는 layer-normalization 과정을 거친다는 것입니다.

이 벡터들과 layer-normalization 과정을 시각화해보면 다음과 같습니다:

이것은 decoder 내에 있는 sub-layer 들에도 똑같이 적용되어 있습니다.
만약 우리가 2개의 encoder과 decoder으로 이루어진 단순한 형태의 Transformer를 생각해본다면 다음과 같은 모양일 것입니다.

The Decoder Side
이때까지 encoder 쪽의 대부분의 개념들에 대해서 얘기했기 때문에, 우리는 사실 decoder의 각 부분이 어떻게 작동하는지에 대해서는 이미 알고 있다고 봐도 됩니다. 하지만, 이제 우리는 이 부분들이 모여서 어떻게 같이 작동하는지에 대해서 보아야 합니다.
Encoding 단계
-
encoder가 먼저 입력 시퀀스를 처리하기 시작합니다.
-
그다음 가장 윗단의 encoder의 출력은 attention 벡터들인 K와 V로 변형됩니다.
-
이 벡터들은 이제 각 decoder의 “encoder-decoder attention” layer에서 decoder 가 입력 시퀀스에서 적절한 장소에 집중할 수 있도록 도와줍니다.

이 encoding 단계가 끝나면 이제 decoding 단계가 시작됩니다.
-
decoding 단계의 각 스텝은 출력 시퀀스의 한 element를 출력합니다 (현재 기계 번역의 경우에는 영어 번역 단어입니다).
-
디코딩 스텝은 decoder가 출력을 완료했다는 special 기호인 <end of sentence>를 출력할 때까지 반복됩니다.
-
각 스텝마다의 출력된 단어는 다음 스텝의 가장 밑단의 decoder에 들어가고 encoder와 마찬가지로 여러 개의 decoder를 거쳐 올라갑니다.
-
encoder의 입력에 했던 것과 동일하게 embed를 한 후 positional encoding을 추가하여 decoder에게 각 단어의 위치 정보를 더해줍니다.

decoder 내에 있는 self-attention layer들은 encoder와는 조금 다르게 작동합니다.
Decoder에서의 self-attention layer은 output sequence 내에서 현재 위치의 이전 위치들에 대해서만 attend 할 수 있습니다.
이것은 self-attention 계산 과정에서 softmax를 취하기 전에 현재 스텝 이후의 위치들에 대해서 masking (즉 그에 대해서 -inf로 치환하는 것)을 해줌으로써 가능해집니다.
“Encoder-Decoder Attention” layer 은 multi-head self-attention과 한 가지를 제외하고는 똑같은 방법으로 작동하는데,
한 가지 차이점은 Query 행렬들을 그 밑의 layer에서 가져오고 Key와 Value 행렬들을 encoder의 출력에서 가져온다는 점입니다.
마지막 Linear Layer과 Softmax Layer
여러 개의 decoder를 거치고 난 후에는 소수로 이루어진 벡터 하나가 남게 됩니다.
어떻게 이 하나의 벡터를 단어로 바꿀 수 있을까요? 이것이 바로 마지막에 있는 Linear layer과 Softmax layer가 하는 일입니다.
Linear layer은 fully-connected 신경망으로 decoder가 마지막으로 출력한 벡터를 그보다 훨씬 더 큰 사이즈의 벡터인 logits 벡터로 투영시킵니다.
우리의 모델이 training 데이터에서 총 10,000개의 영어 단어를 학습하였다고 가정하자 (이를 우리는 모델의 “output vocabulary”라고 부른다).
그렇다면 이 경우에 logits vector의 크기는 10,000이 될 것이다 – 벡터의 각 셀은 그에 대응하는 각 단어에 대한 점수가 된다. 이렇게 되면 우리는 Linear layer의 결과로써 나오는 출력에 대해서 해석을 할 수 있게 됩니다.
그다음에 나오는 softmax layer는 이 점수들을 확률로 변환해주는 역할을 합니다. 셀들의 변환된 확률 값들은 모두 양수 값을 가지며 다 더하게 되면 1이 됩니다. 가장 높은 확률 값을 가지는 셀에 해당하는 단어가 해당 스텝의 최종 결과물로서 출력되게 됩니다.

위의 그림에 나타나 있는 것과 같이 decoder에서 나온 출력은 Linear layer와 softmax layer를 통과하여 최종 출력 단어로 변환됩니다.
학습 과정 다시 보기
자 이제 학습된 Transformer의 전체 forward-pass 과정에 대해서 알아보았으므로, 이제 모델을 학습하는 방법에 대해서 알아보겠습니다.
학습 과정 동안, 학습이 되지 않은 모델은 정확히 같은 forward pass 과정을 거칠 것입니다.
그러나 label이 있는 학습 데이터 셋을 학습시키는 중이므로 우리는 모델의 결과를 실제 정답과 비교할 수 있습니다.
이 학습 과정을 시각화하기 위해, 우리의 output vocabulary 가 6개의 단어만 ((“a”, “am”, “i”, “thanks”, “student”, and “<eos>” (‘end of sentence’의 줄임말))) 포함하고 있다고 가정하겠습니다.

모델의 output vocabulary는 학습을 시작하기 전인 preprocessing 단계에서 완성됩니다.
이 output vocabulary를 정의한 후에는, 우리는 이 vocabulary 크기의 벡터를 이용하여 각 단어를 표현할 수 있습니다. 이것은 one-hot encoding이라고도 불립니다. 그러므로 우리의 예제에서는, 단어 “am”을 다음과 같은 벡터로 나타낼 수 있습니다

이제 모델의 loss function에 대해서 얘기해보겠습니다.
이것은 학습 과정에서 최적화함으로써 모델을 정확하게 학습시킬 수 있게 해주는 값입니다.
Loss Function
우리가 모델을 학습하는 상황에서 가장 첫 번째 단계라고 가정합시다. 그리고 우리는 학습을 위해 “merci”라는 불어를 “thanks”로 번역하는 간단한 예시를 생각하겠습니다.
이 말은 즉, 우리가 원하는 모델의 출력은 “thanks”라는 단어를 가리키는 확률 벡터란 것입니다. 하지만 우리의 모델은 아직 학습이 되지 않았기 때문에, 아직 모델의 출력이 그렇게 나올 확률은 매우 작습니다.
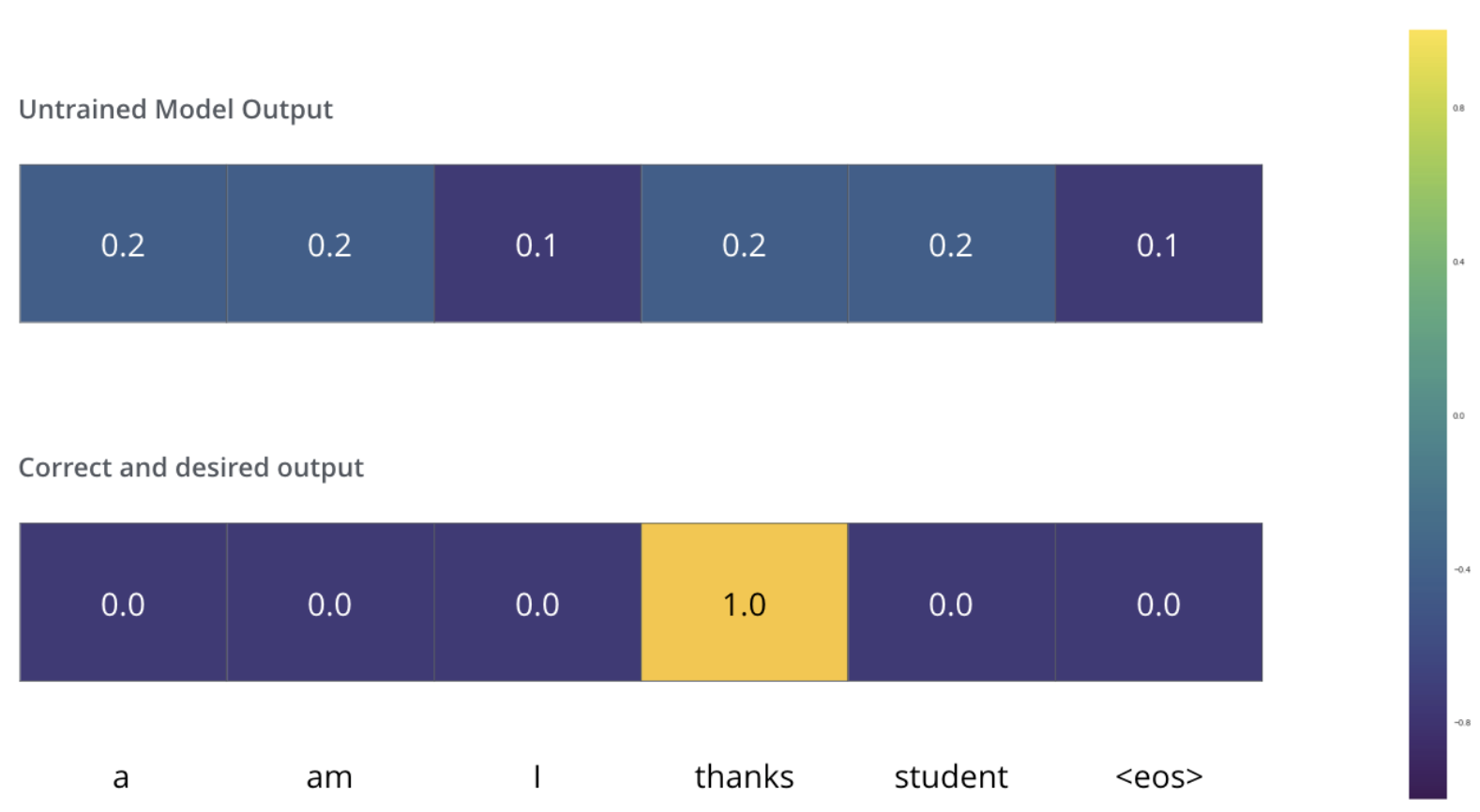
학습이 시작될 때 모델의 parameter들 즉 weight들은 랜덤으로 값을 부여하기 때문에, 아직 학습이 되지 않은 모델은 그저 각 cell (word)에 대해서 임의의 값을 출력합니다. 이 출력된 임의의 값을 가지는 벡터와 데이터 내의 실제 출력 값을 비교하여, 그 차이와 backpropagation 알고리즘을 이용해 현재 모델의 weight들을 조절해 원하는 출력 값에 더 가까운 출력이 나오도록 만듭니다.
그렇다면 두 확률 벡터를 어떻게 비교할 수 있을까요? 간단합니다. 하나의 벡터에서 다른 하나의 벡터를 빼버립니다. cross-entropy와 Kullback–Leibler divergence를 보시면 이 과정에 대해 더 자세한 정보를 얻을 수 있습니다.
하지만 여기서 하나 주의할 것은 우리가 고려하고 있는 예제가 지나치게 단순화된 경우란 것입니다. 조금 더 현실적인 예제에서는 한 단어보다는 긴 문장을 이용할 것입니다. 예를 들어 입력은 불어 문장 “je suis étudiant”이며 바라는 출력은 “i am a student”일 것입니다.
이 말은 즉, 우리의 모델이 출력할 확률 분포에 대해서 바라는 것은 다음과 같습니다:
-
각 단어에 대한 확률 분포는 output vocabulary 크기를 가지는 벡터에 의해서 나타내 집니다 (우리의 간단한 예제에서는 6이지만 실제 실험에서는 3,000 혹은 10,000과 같은 숫자일 것입니다).
-
decoder가 첫 번째로 출력하는 확률 분포는 “i”라는 단어와 연관이 있는 cell에 가장 높은 확률을 줘야 합니다.
-
두 번째로 출력하는 확률 분포는 “am”라는 단어와 연관이 있는 cell에 가장 높은 확률을 줘야 합니다.
-
이와 동일하게 마지막 ‘<end of sentence>‘를 나타내는 다섯 번째 출력까지 이 과정은 반복됩니다 (‘<eos>’ 또한 그에 해당하는 cell을 벡터에서 가집니다).

위의 그림은 학습에서 목표로 하는 확률 분포를 나타낸 것입니다.
모델을 큰 사이즈의 데이터 셋에서 충분히 학습을 시키고 나면, 그 결과로 생성되는 확률 분포들은 다음과 같아질 것입니다

학습 과정 후에, 바라건대, 모델은 정확한 번역을 출력할 것입니다. 물론, 우리가 예제로 쓴 문장이 학습 데이터로 써졌다는 보장은 없습니다 (cross validation을 참고하세요).
한 가지 여기서 특이한 점은, 학습의 목표로 하는 벡터들과는 달리, 모델의 출력 값은 비록 다른 단어들이 최종 출력이 될 가능성이 거의 없다 해도 모든 단어가 0보다는 조금씩 더 큰 확률을 가진다는 점입니다 – 이것은 학습 과정을 도와주는 softmax layer의 매우 유용한 성질입니다.
모델은 한 타임 스텝 당 하나의 벡터를 출력하기 때문에 우리는 모델이 가장 높은 확률을 가지는 하나의 단어만 저장하고 나머지는 버린다고 생각하기 쉽습니다. 그러나 그것은 greedy decoding이라고 부르는 한 가지 방법일 뿐이며 다른 방법들도 존재합니다.
예를 들어 가장 확률이 높은 두 개의 단어를 저장할 수 있습니다 (위의 예시에서는 ‘I’와 ‘student’). 그렇다면 우리는 모델을 두 번 돌리게 됩니다. 한 번은 첫 번째 출력이 ‘I’이라고 가정하고 다른 한 번은 ‘student’라고 가정하고 두 번째 출력을 생성해보는 것이죠. 이렇게 나온 결과에서 첫 번째와 두 번째 출력 단어를 동시에 고려했을 때 더 낮은 에러를 보이는 결과의 첫 번째 단어가 실제 출력으로 선택됩니다.
이 과정을 두 번째, 세 번째, 그리고 마지막 타임 스텝까지 반복해 나갑니다. 이렇게 출력을 결정하는 방법을 우리는 “beam search”라고 부르며, 고려하는 단어의 수를 beam size, 고려하는 미래 출력 개수를 top_beams라고 부릅니다.
우리의 예제에서는 두 개의 단어를 저장했으므로 beam size가 2이며, 첫 번째 출력을 위해 두 번째 스텝의 출력까지 고려했으므로 top_beams 또한 2인 beam search를 한 것입니다. 이 beam size와 top_beams는 모두 우리가 학습 전에 미리 정하고 실험해볼 수 있는 hyperparameter들입니다.
더 깊이 Transformer 알아보기
이 글이 Transformer의 주요 개념들을 대략적으로 잘 설명한 소개 글이 되었길 바랍니다. 만약 Transformer에 대해 더 자세히 알고 싶으시다면 다음 자료들을 추천합니다:
-
Attention Is All You Need 논문과 구글에서 작성한 공식 Transformer 블로그 글 (Transformer: A Novel Neural Network Architecture for Language Understanding)을 읽으세요. Tensor2Tensor 발표 글 도 추천합니다.
-
모델과 세부사항들을 설명하는 저자 Łukasz Kaiser의 발표를 시청하세요.
-
Tensor2Tensor repository의 부분으로서 제공된 Jupyter Notebook을 가지고 놀아보세요.
-
Tensor2Tensor repo를 둘러보세요.
Transformer를 활용한 follow-up 연구들로는 다음이 있습니다:
'NLP > Basics' 카테고리의 다른 글
| [Attention] Bahdanau Attention이란? (2) | 2020.07.17 |
|---|---|
| Seq2Seq with Attention정리 (2) | 2020.05.07 |
| 코퍼스(Corpus), 말뭉치란? (0) | 2020.04.18 |
- Total
- Today
- Yesterday
- 오디오 전처리
- MFCC
- MIT
- keras
- LSTM
- boto3
- lambda
- wavenet
- stft
- 인공지능 스피커 호출
- RNN
- AWS
- netron
- TF2.0
- 시계열
- nlp
- 모델 시각화
- librosa
- nlp 트렌드
- 알고리즘
- 핵심어 검출
- 6.006
- Introduction to Algorithm
- S3
- 알고리즘 강의
- BOJ
- aws cli
- Tensorflow2.0
- nlg
- tensorflow
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |